Next-generation, enterprise-grade MPP database unlocking 5-10x analytical performance improvements over competitors
Last September, StarRocks opened its source code to global communities, and communities have become a key driving force behind improving StarRocks. StarRocks received over 2,000 GitHub stars in the first 135 days of opening code. Hundreds of large and medium-sized businesses are drawn to StarRocks.
2x the performance of single-table queries vs. competitors
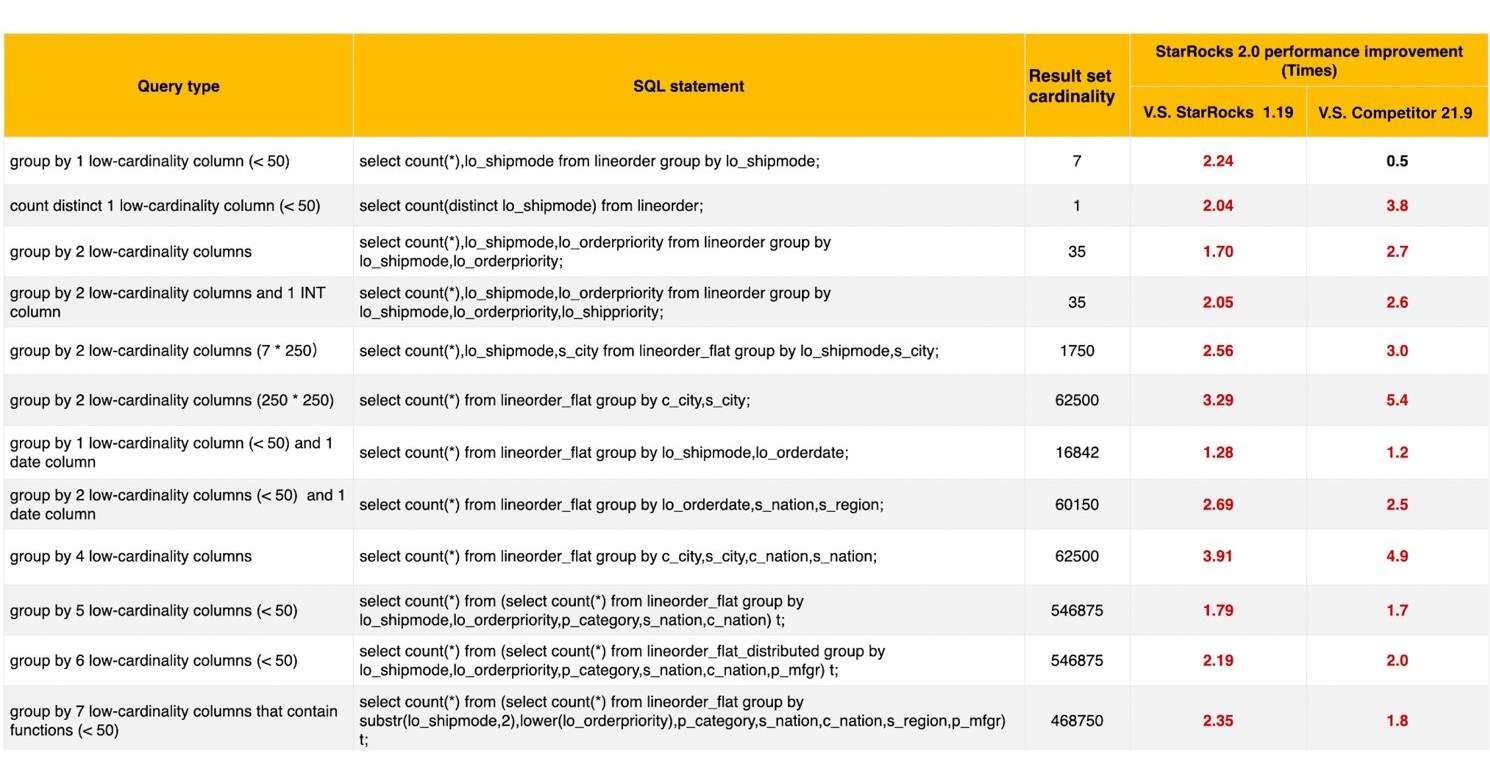
StarRocks 2.0 is ideal for single-table and multi-table queries. For single-table queries, StarRocks 2.0 innovatively uses global dictionaries to optimize queries on low-cardinality fields, delivering twice the single-table query performance of its previous versions and also other major vendors. database services. For multi-table queries, StarRocks 2.0 dropped the cost-based optimizer (CBO) to handle complex multi-table queries, improving multi-table query performance by two times and making StarRocks 2.0 five to ten times faster than other database systems.
In terms of data updates, traditional OLAP systems use merge-on-read mode to update data, which is not the best solution because it seeks data loading efficiency at the expense of data performance. requests. As the requirements for real-time data updates continue to increase in the finance and logistics industries, this model no longer meets expectations. StarRocks 2.0 introduces a new data model, the primary key model, for updating data in delete and insert mode. This innovation improves query performance by three to ten times in real-time update scenarios.
Additionally, the memory management scheme has been redesigned in StarRocks 2.0 to improve system stability. A pipeline execution engine designed for higher concurrency and faster complex queries on multi-core machines has been released for trial use. This engine will be officially released in StarRocks 2.1.
Five technical highlights and R&D orientations in 2022
StarRocks announced its five major R&D directions in 2022 to the community.
Resource management
StarRocks will introduce a new resource management mechanism to provide separate resource pools for different companies. This mechanism guarantees sufficient resource quotas and isolated resources for enterprises. This way, different services can run on the same cluster, which simplifies operation and maintenance and improves cluster resource utilization.
Materialized views with JOIN
Data modeling in majority of enterprises requires complex data development by data engineers. Materialized views with JOIN allow data engineers to create different types of materialized views to build data models. This significantly reduces the workload for data engineers and simplifies data modeling.
StarRocks also introduces smart materialized views. This feature intelligently recommends materialized views to users based on query behavior to speed up queries.
Separation of storage and compute
In earlier versions of StarRocks, compute and storage are tightly coupled for excellent query performance. However, this architecture does not allow the allocation of resources on demand and can lead to unnecessary costs. In 2022, StarRocks will implement a new architecture where storage and compute will be decoupled. This new architecture supports offline scanning in parallel with real-time scanning and can be deployed across public, private, and multiple clouds.
Rapid data lake analysis
Currently, StarRocks is more like a data warehouse. Customers import high-value data from data lakes into StarRocks for lightning-fast data analysis. In 2022, StarRocks will continue its efforts to improve data lake analytics capabilities and provide a unified, lightning-fast analytics experience for customers.
The StarRocks community has completed the first phase of developing data queries on Iceberg, with collaboration from communities and renowned developers from the world’s leading cloud computing companies. Test results show that StarRocks offers 5x performance improvement compared to Trino. In the future, the StarRocks community will expand its support for Hudi and provide more feature enhancements.
Unified batch and stream processing
StarRocks plans to implement unified stream and batch processing across hundreds of nodes. This way, raw customer data can be processed and then analyzed in StarRocks. This ensures a single, unified and lightning-fast data processing and analysis experience, taking the vision of unification to a new level.
About StarRocks
StarRocks is a next-generation MPP database designed for all analytical scenarios. It features a simple architecture, vectorized engine, redesigned CBO, and query speed (especially for multi-table join queries) beyond the reach of other database products. StarRocks supports real-time data analysis and performs efficient queries on real-time updated data. StarRocks provides materialized views to further speed up queries. Customers can use StarRocks to flexibly create various patterns such as flat tables and star and snowflake patterns. StarRocks is compatible with the MySQL protocol and can interconnect with various MySQL clients and tools. StarRocks does not rely on any external system. The simple architecture makes it highly available, scalable, and easy to operate and maintain.
StarRocks meets the requirements of various data analysis scenarios, such as multidimensional filtering and analysis, real-time data analysis, and ad hoc queries. It allows the access of thousands of users at the same time. Typical usage scenarios include business intelligence, real-time data warehousing, user profiling, reports and dashboards, order analytics, O&M and monitoring, analytics anti-fraud and risk management. Hundreds of large and medium-sized enterprises in various industries have deployed StarRocks in their production environments and have seen thousands of StarRocks servers running stably and consistently on their platforms.
SOURCEStar Rocks